It has been a while since I made a blog post but this new one has to do with AI agents and automation. I just started to dive into n8n which is a node based workflow system with so many possibilities.
More Powerful AI
Upgrade Alert! I recently upgraded to an NVIDIA 3060 with 12GB VRAM—a budget-friendly choice that’s made a huge difference. Now, I can run 8K and 14K AI models with minimal issues. Try this hardware upgrade for similar performance gains!
Goal of the Automation
- Receive tech news via XDA RSS feed
- Filter out irrelevant articles
- Present only relevant news for the user
Workflow
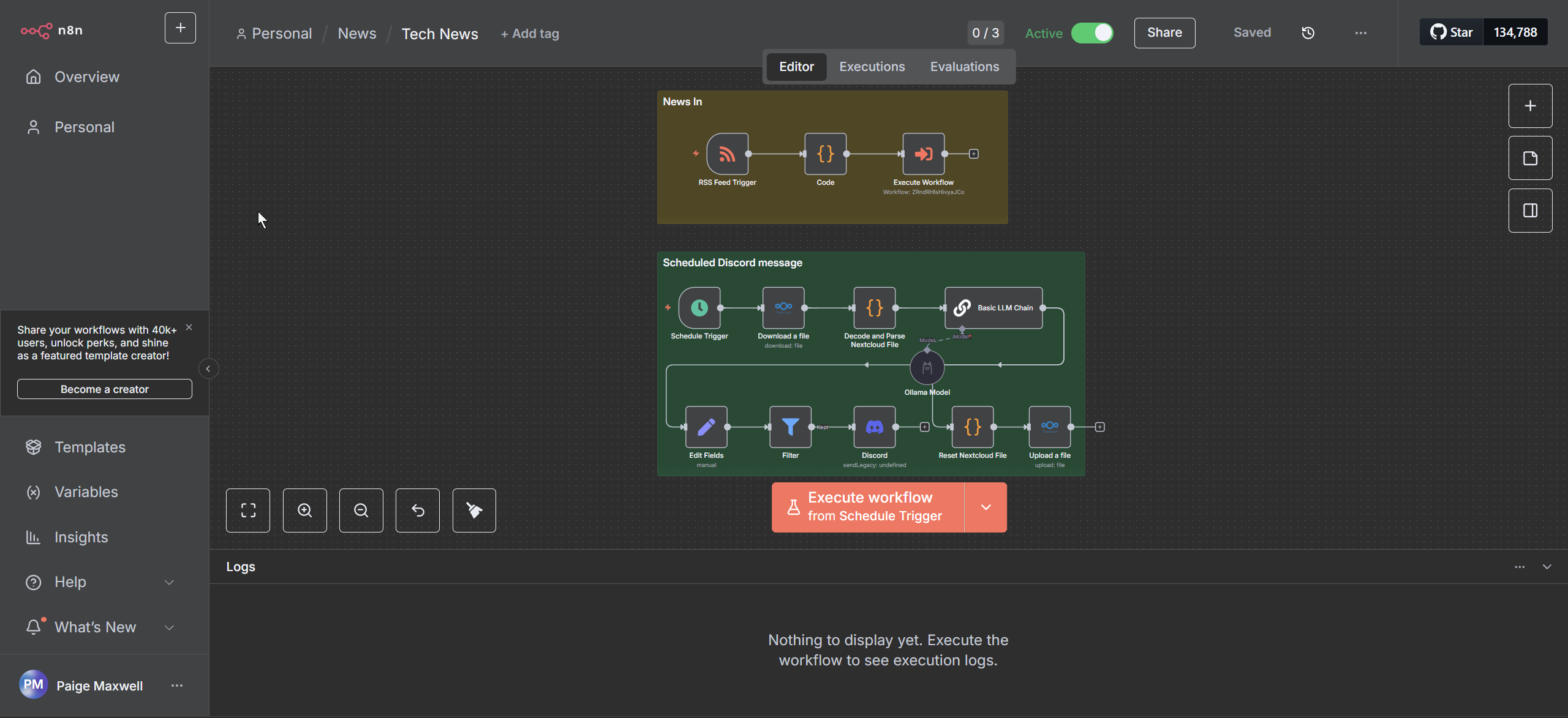 The “News In” aggregator runs every minute, converting RSS JSON input into a pipe-delimited CSV file:
The “News In” aggregator runs every minute, converting RSS JSON input into a pipe-delimited CSV file:
1
|
title|creator|link|content
|
Fields included:
titlecreatorlinkcontent
The code block takes the RSS JSON input and converts it into a pipe delimited CSV File.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
const obj = {
title: $input.first().json.title,
creator: $input.first().json.creator,
link: $input.first().json.link,
content: $input.first().json['content:encodedSnippet']
};
const contentString = obj.content.replace(/\n/g, '').replace(/\\\"/g, '"');
const csvString = obj.title + '|' + obj.creator + '|' + obj.link + '|' + contentString
return [
{
json: {
content: csvString,
},
},
];
|
The reason it is written to the file is so the AI can look over everything collected within a certain time frame later on.
The second part of the workflow starts with a time based trigger set to 7:00am then it downloads the csv file from Nextcloud.
Nextcloud files downloaded are still base64 encoded and need to be decoded that is what the first code block is for.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// Get the Base64-encoded data from the previous node
const base64Data = $input.item.binary.data.data;
// Create a Buffer from the Base64 string
const buffer = Buffer.from(base64Data, 'base64');
// Convert the buffer to a string for CSV manipulation
const dataString = buffer.toString('utf8');
// Convert to JSON
const lines = dataString.split('\n');
const result = [];
for (let i = 1; i < lines.length; i++) {
const line = lines[i].split('|');
const item = {};
// Map the headers to the corresponding values
item.title = line[0] || '';
item.creator = line[1] || '';
item.link = line[2] || '';
item.content = line[3] || '';
result.push(item);
}
// Return the data wrapped in the required n8n format
return result;
|
The returned results are fed into the AI for analysis. It will read over each articles summary and determine if it’s relevant based on its prompt.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
**Objective:**
Classify and summarize RSS tech news articles based on specific categories, and determine their relevance to a defined set of topics.
---
## **Instructions**
1. **Input:**
You will receive a **tech news article summary** (text) from an RSS feed.
2. **Categories to Check:**
Determine if the article is related to **any** of the following topics:
- Homelab
- Raspberry Pi
- Proxmox
- Linux
- Open-source
- Self-hosted
- Docker
3. **Summary:**
Provide a **concise summary** of the article (max 2-3 sentences) that highlights its main content and relevance to the topics.
4. **Relevance Check:**
Set `"isRelevant"` to `true` if the article **mentions at least one** of the listed categories. Otherwise, set it to `false`.
5. **Output Format:**
Return a **structured JSON** object with the following keys:
- `"isRelevant"` (boolean): Whether the article is relevant to the specified topics.
- `"summary"` (string): A brief summary of the article.
---
## **Example Response**
json
{
"output": {
"isRelevant": true,
"summary": "This article discusses features of Network-Attached Storage distributions such as ZFS and Btrfs, which include Copy-on-Write and checksum facilities. It also mentions the possibility of setting up a reliable RAID cluster with spare storage drives in a home lab environment."
}
}
---
## **Clarifications**
- **Relevance Threshold:** An article is relevant **only if it explicitly mentions at least one** of the listed topics.
---
## **Edge Cases**
- **No Matches:**
json
{
"output": {
"isRelevant": false,
"summary": "A breakthrough in quantum computing was announced by a research team."
}
}
- **Partial Match:**
json
{
"output": {
"isRelevant": true,
"summary": "Raspberry Pi Foundation announces a new educational initiative for open-source projects."
}
}
---
**Note:** Ensure the JSON output is valid and free of syntax errors.
---
# INPUT:
{{ $json.content }}
|
This is where the workflow splits and does two things. The csv file get’s overwritten with a new one with only headers thus resetting the file and the AI’s output is combined with the other article information and is filtered based on the output of No output. A message is generated for discord and a webhook is used to send a message with the title, creator, link and the AI’s summary of the article for me to read later.
Reset Nextcloud File
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
const newDataString = 'title|creator|link|content';
// Convert the new CSV string back to Base64
const newBase64String = Buffer.from(newDataString, 'utf8').toString('base64');
// Set the new Base64 string as the binary data for the next node
const output = {
json: {
// You can add any JSON data you need for the next node
message: 'New binary data created successfully.'
},
binary: {
// Define the new binary data object
myData: {
data: newBase64String, // This is a Base64 string for "hello binary data"
fileName: 'modified_file.csv',
mimeType: 'text/csv'
}
}
};
return output;
|
Discord Message
1
2
3
4
5
|
**{{ $json.title }}**
**Author:** {{ $json.creator }}
**Summary:** {{ $json.content }}
{{ $json.link }}
|
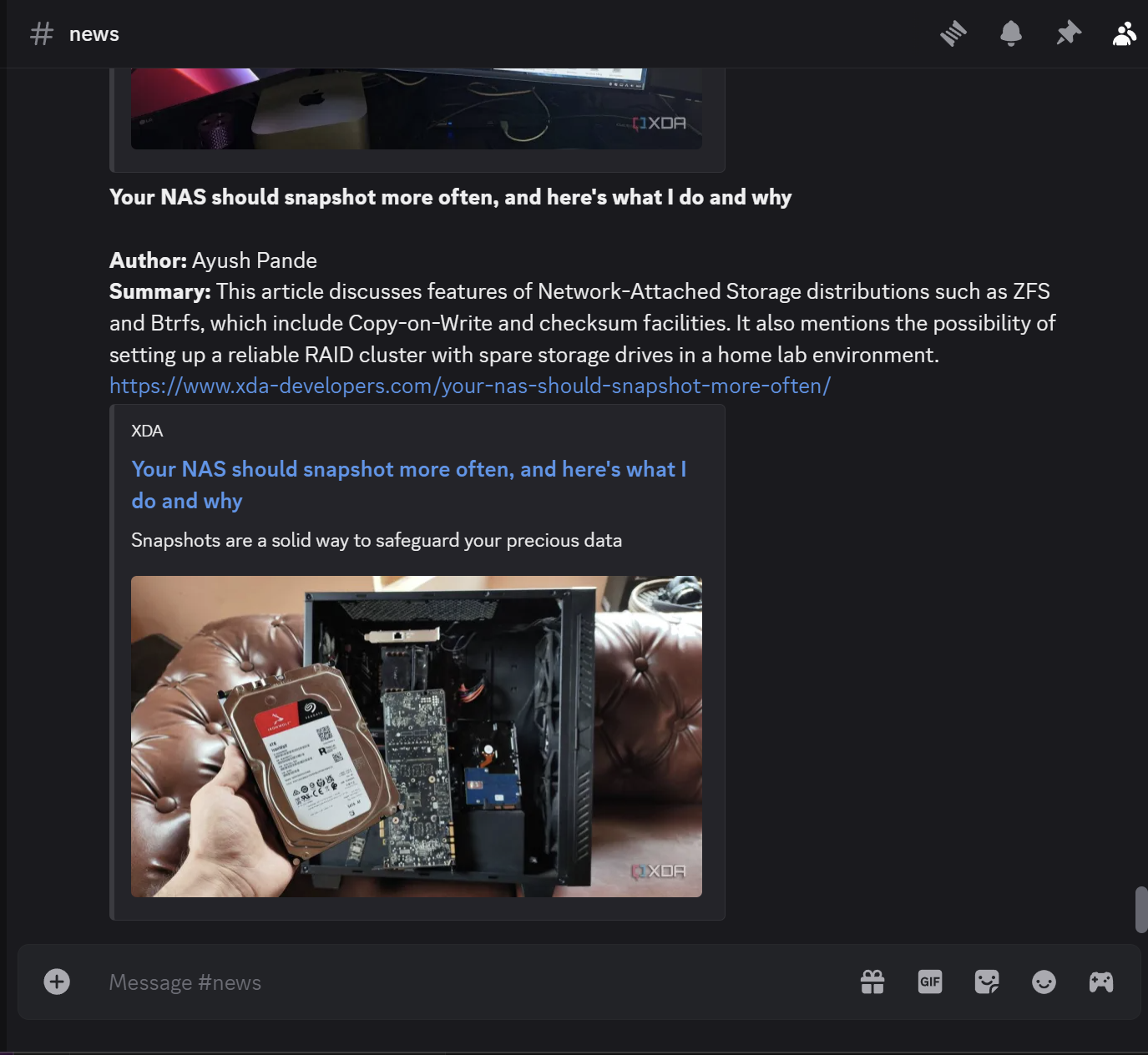
I plan on duplicating and modifying this feed for other news sources just by changing the CSV file it writes to and the AI’s Prompt!
